下载说明本作品里面包括调试教程和开发工具和软件,可自行下载根据教程进行调试!
如需技术协助调试,本站收取50元作品调试费!点此申请调试
如果上面没有找到适合您需求的作品,您可联系我们为您定做,定做的作品完全按照您的功能需求来做,并且后期三包,包调试,包讲解,包修改直到通过为止。
互联网被普及前,人们查阅资料首先想到的便是拥有大量书籍的图书馆,而在当今很多人都会选择一种更方便、快捷、全面、准确的方式——互联网.如果说互联网是一个知识宝库,那么搜索引擎就是打开知识宝库的一把钥匙.搜索引擎是随着WEB信息的迅速增加,从1995年开始逐渐发展起来的技术,用于帮助互联网用户查询信息的搜索工具.搜索引擎以一定的策略在互联网中搜集、发现信息,对信息进行理解、提取、组织和处理,并为用户提供检索服务,从而起到信息导航的目的.目前搜索引擎已经成为倍受网络用户关注的焦点,也成为计算机工业界和学术界争相研究、开发的对象.
目前较流行的搜索引擎已有Google,Yahoo, Info seek, baidu等. 出于商业机密的考虑, 目前各个搜索引擎使用的Crawler系统的技术内幕一般都不公开, 现有的文献也仅限于概要性介绍. 随着Web 信息资源呈指数级增长及Web 信息资源动态变化, 传统的搜索引擎提供的信息检索服务已不能满足人们日益增长的对个性化服务的需要, 它们正面临着巨大的挑战. 以何种策略访问Web,提高搜索效率, 成为近年来专业搜索引擎网络爬虫研究的主要问题之一。
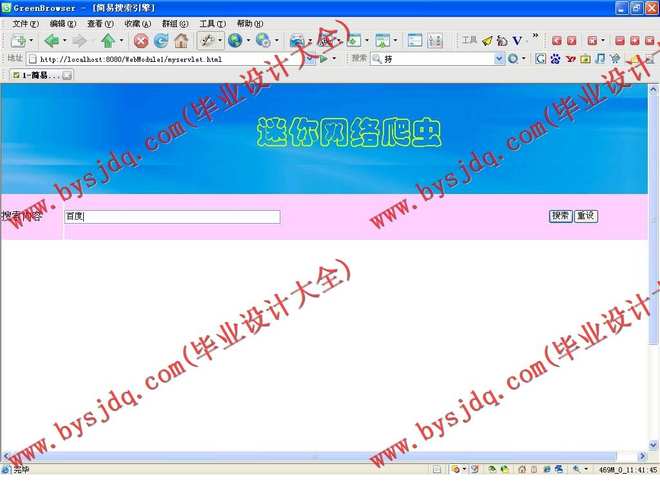
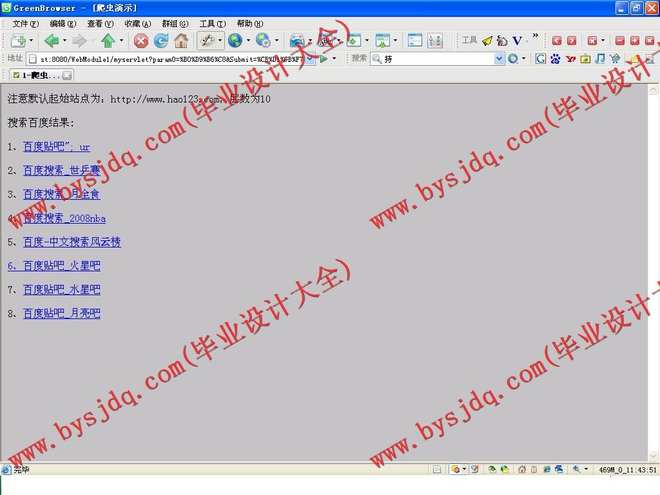
标签:网络爬虫,搜索引擎



